



Недавно прошедшая конференция optapro вышла разносторонней, видны тренды с исследованиями, использующими трэккинговые данные и направление с контекстным представлением. Стало сильно больше презентаций с нейросетевыми моделями. Одна из причин, по которой интересно наблюдать за подобными форумами — люди, которые приходят из абсолютно разных сфер и применяют в футболе свои профессиональные скилы. Пару лет назад, например, выступал профессор экономики с своим студентом и показывал как их экономическая модель помогает в матчменеджменте.
Я решил подробнее разобрать первую презентацию по нескольким причинам: попытка описать стиль команд с помощью контекста, простые данные, которые при желании достанет любой, кто хочет попробовать (нужны только количественные данные по матчам), модель, изначально сделанная для работы с текстовыми документами.

Выступавшие поставили цель — описать стиль команд, взяв все сыгранные матчи и базовую статистику по ним. Далее, зная результаты матчей и имея математическое представление стиля, посчитать, какой стиль более эффективен против стиля соперника.
Лучше всего эту идею проиллюстрирует мем из презентации:
В своей работе исследователи используют модель Latent Dirichlet Allocation — относительно старая модель из классического машинного обучения для задач анализа естественного языка. Она была представлена в 2000 году и с тех пор использовалась для кластеризации текстовых документов. От любого другого алгоритма кластеризации LDA отличается тем, что генерирует более-менее осмысленные кластеры (их принято называть топиками).
Для примера представим, что текстовые документы — это разные новости: спортивные, политические, научные и тд. Каждый документ состоит из слов, которые его, по сути, определяют. LDA безразличен к порядку этих слов, имеет значение только количество конкретных слов в конкретных документах (отчасти это минус, но в нашей задаче это, наоборот, плюс). Модель на каждом шаге обучения уточняет топики (их количество изначально задаётся как параметр). Топик — это всего лишь набор слов с их важностью (число от 0 до 1). После обучения по готовым топикам уже можно кластеризовать документы — это несложно: если топик — это слова и их важность, а документ — слова и их частота в этом документе, то умножая важность слова для каждого топика на его частоту в документе, мы и получим наиболее вероятный топик. Например, в случае с тремя типами новостей топики, вероятно, будут выглядеть так:
- футбол * 0.9, хоккей * 0.85, сборная * 0.7, страна * 0.5 …
- закон * 0.95, порядок * 0.7, страна * 0.6 …
- открытие * 0.9, исследование * 0.8…
Возможно, вы заметили, что слово страна используется сразу в двух топиках — это нормально.
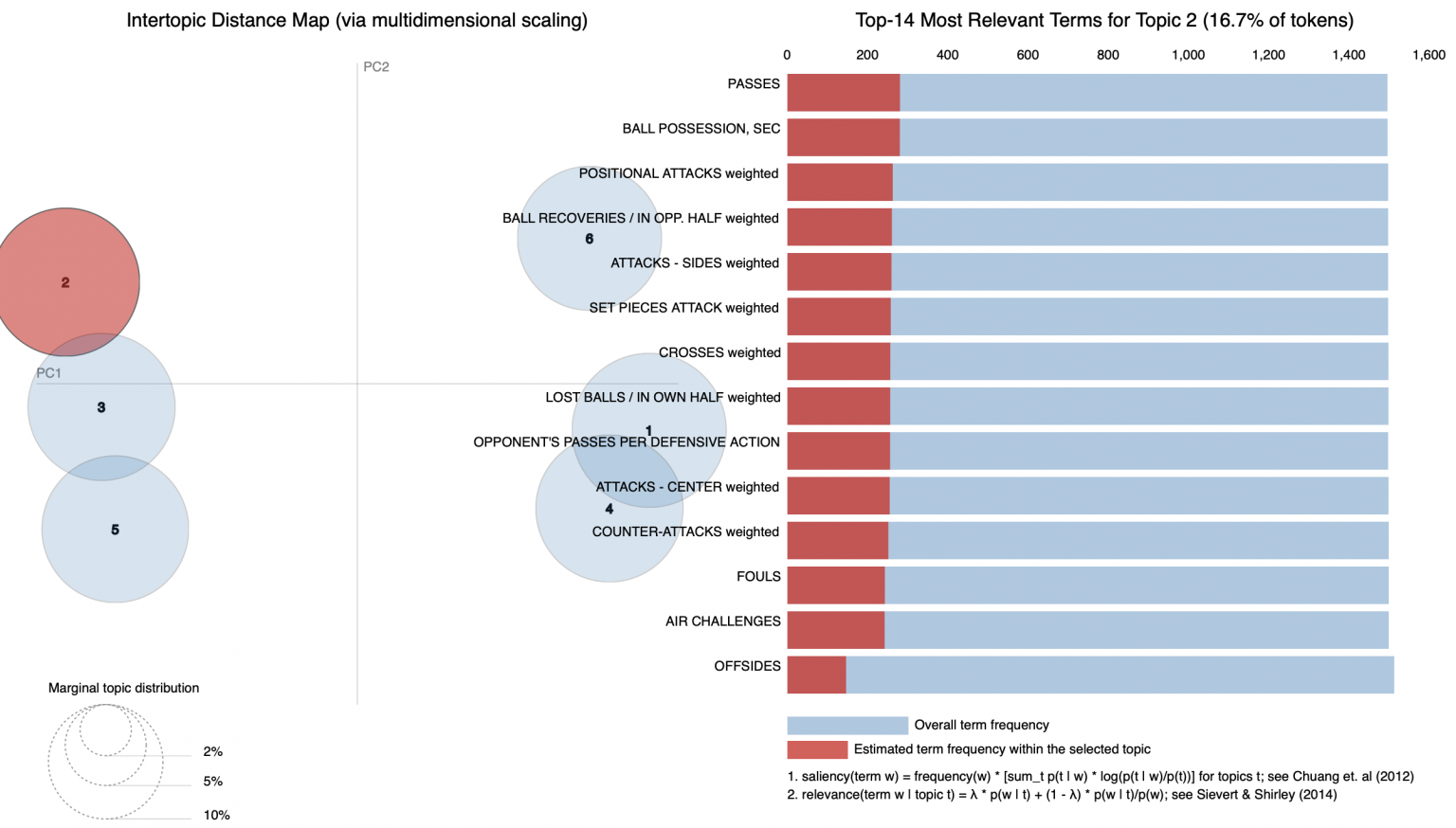
Пример работы LDA на каком-то датасете с текстовыми документами с пояснением к топику 1
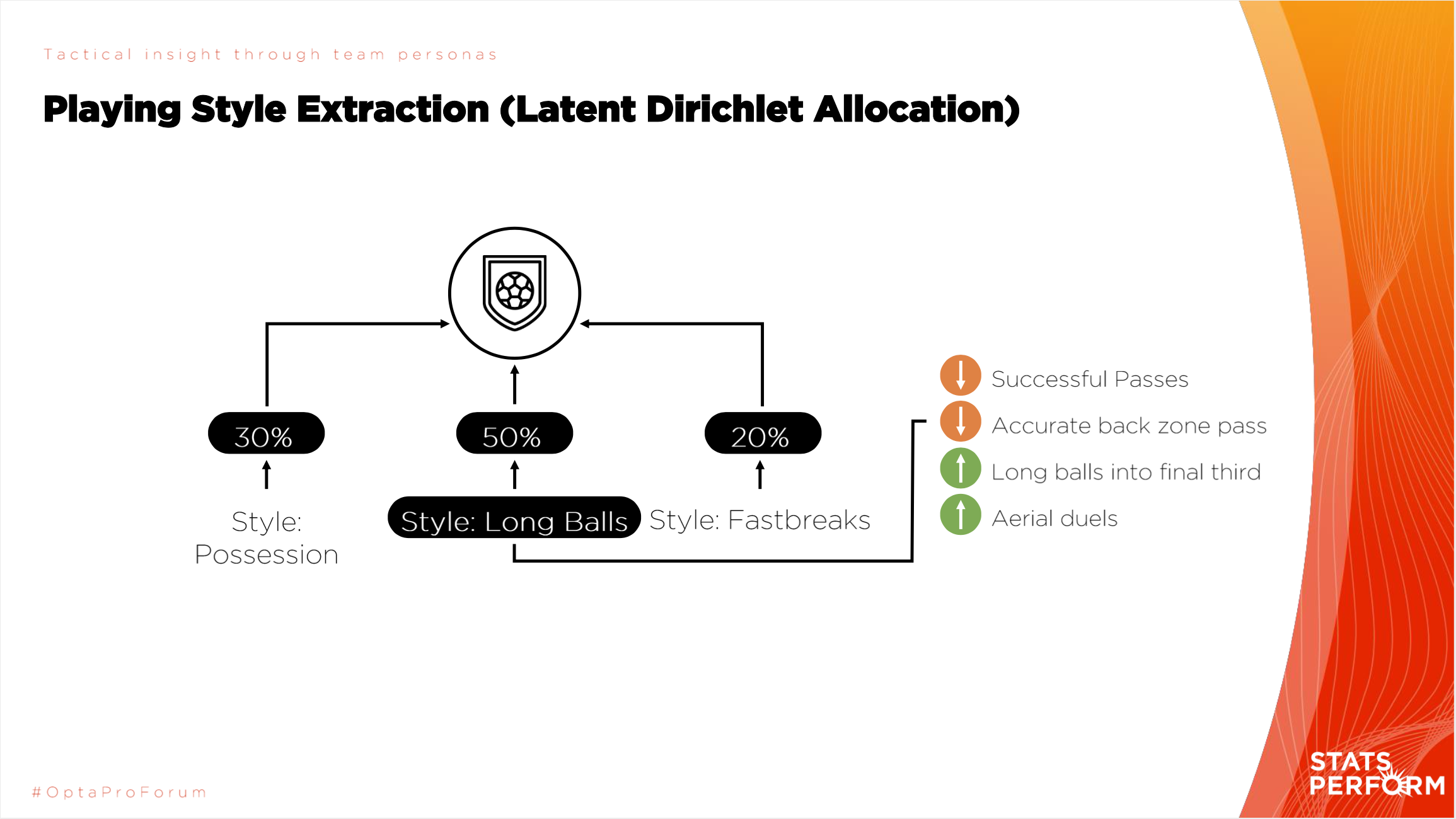
В футболе все аналогично: вместо документов у нас матчи, а вместо слов — количественная информация об эвентах, например, количество пасов под удар, количество навесов, среднее количество передач соперника на оборонительное действие, владение мячом и тд. Очевидно, что топики (определяющие стиль команды) будут состоять из ключевых для этого стиля эвентов, например, по топику с ключевыми словами владение и контрпрессинг мы подумаем, что команда играет в условный позиционный футбол, а по словам навесы и воздушные дуэли мы подумаем, что это «Севилья».
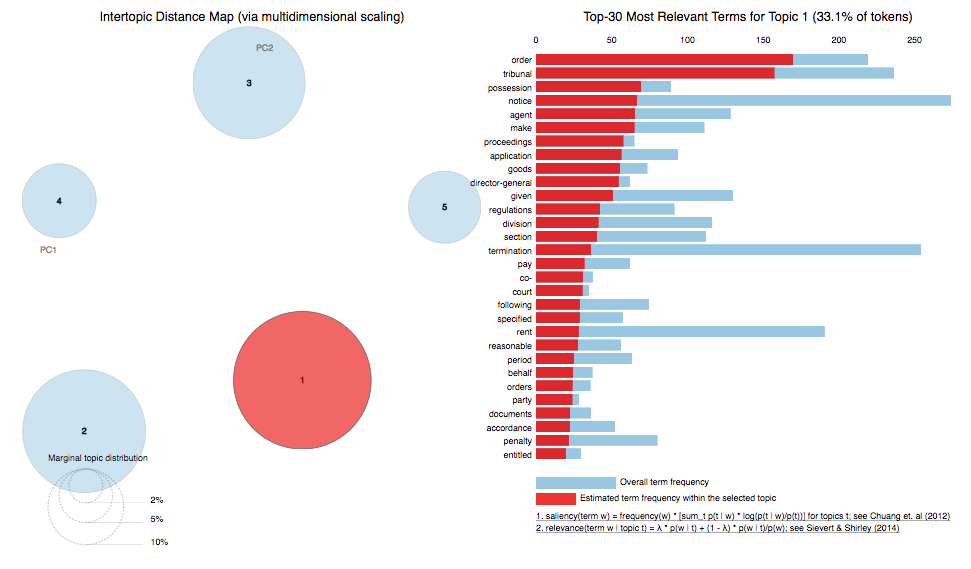
Слайд из оригинальной презентации. Пример кластеризации LDA на три кластера на футбольных данных с пояснением с одному из кластеров
В реальности топики намного более сложные и многогранные, и команды не будут относиться целиком к одному стилю, а будут распределены между ними, но об этом подробнее позже.
Авторы презентации показали формулу, благодаря которой можно оценить потенциальное количество голов, которое команда A забьет команде B. Все просто: нужно знать качество атаки команды A, качество обороны команда B и насколько эффективен стиль A против стиля B (сейчас это число от -1 до 1). Вычитая из первого второе и прибавляя эффективность, должно получиться примерное количество забитых мячей командой A.
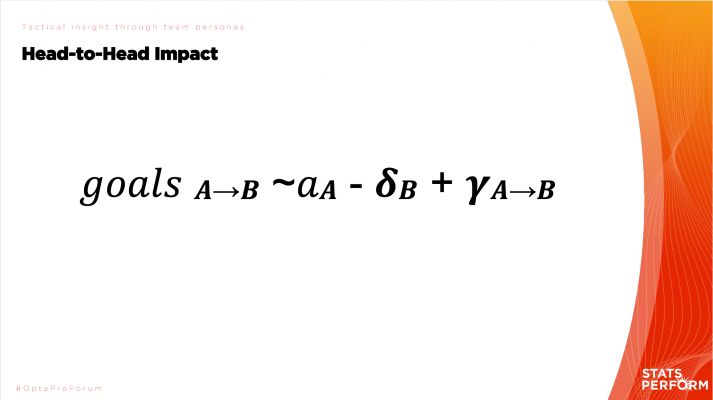
Слайд из оригинальной презентации. Формула для аппроксимации количества голов, забитых командой A команде B
Так как найти эту эффективность? Начнем с того, что у нас есть таблица, по которой мы строили топики, в ней должна быть информация о голах и о сопернике. В таком случае, можно выразить эффективность из формулы и посчитать ее, так как все остальное нам известно.
Для упрощения задачи в качестве оценки атаки команды я использовал среднее количество забитых голов за матч, а для оценки обороны использовал среднее отклонение забитых мячей соперника от его среднего количества забитых мячей (то есть насколько больше/меньше соперник забивает команде относительно того, сколько он забивает в среднем за матч).
Для каждого матча определяется количество голов, забитое командой A, топик команды A в этом матче, топик команды B в этом матче (уже должны быть посчитаны среднее количество забитых A и среднее соперников B). Далее из количества забитых A вычитается среднее количество забитых A и прибавляется среднее отклонение соперников B. Это значение сохраняется для эффективности топика Ta против Tb. Затем все эффективности для каждого противостояния усредняются, так и подтянется искомое значение.
Как проверить — не бред ли это все? Легко: уберем из формулы эффективность и посмотрим среднюю разницу между качеством атаки A и качества обороны B с реальным количеством голов A в матчах. Потом проведем такое же сравнение с учётом эффективности.
Далее в презентации рассматриваются нелинейные зависимости, но это тема для отдельного поста, здесь речь теперь пойдет более подробно о моей реализации этой модели, подводных камнях в работе с данными и визуализациями.
Дойдя до этого момента, может показаться, что все очень просто — берём любую таблицу с общей статистикой, подаем ее в LDA и получаем идеальные топики, которые полностью описывают стиль команды. И каждая команда будет целиком находиться в одном топике. Далее по схеме легко выражается и считается эффективность. На самом деле все не так. Проблемы начинаются с данными — мы не можем напрямую контролировать или задавать топики, а надеяться на то, что они сразу сами получатся такие, какие нужно, не стоит.
Важная ремарка в презентации — “убрать нестилистические параметры из таблицы и нормализовать”. На самом деле это сложный процесс, который не получится сделать за один раз, опишу далее немного подробнее. Вторая важная проблема — определение топика по статистике одного матча/команды в целом. Очень редкая ситуация, когда команда целиком принадлежит одному топику, а если это так, то, скорее всего, топики будет очень сложно интерпретировать. Из этого рождается ещё одна проблема — на этапе расчета эффективности командам по матчу присуждаются топики, для которых идёт подсчет. Так как команда, скорее всего, не будет находиться в одном топике, то мы теряем часть контекста, из-за чего падает точность.
Я взял статистику по всем командам из топ-4 + РПЛ в этом сезоне. Данные в таблице разделил на три типа: обычные количественные данные (пасы, кроссы, фолы, прессинг действия), обратные данные (PPDA — чем меньше, тем лучше), относительные данные (атаки через фланги, атаки через центр, контратаки, позиционные атаки). В зависимости от типа менялась нормализация — обычные данные нормализовывались стандартным образом, обратные — вместо нормализации возводил в минус первую степень, в относительных считал относительное количество эвентов (например, для атак через фланги — относительное количество фланговых атак от общего количества атак).
Часть таблицы до нормализации:
Часть таблицы после отсева лишних параметров и нормализации оставшихся:
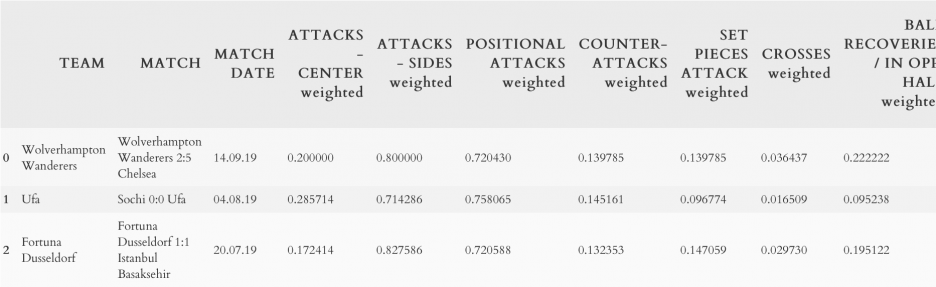
Далее важно убрать смещенность выборки:
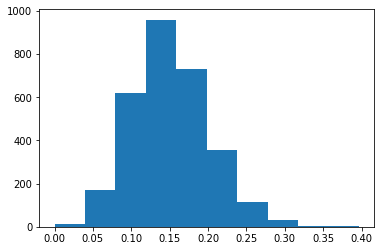
Гистограмма с распределением весов контратак после нормализации; видно, что в среднем значение находится около 0.15
Чтобы все параметры были в равных условиях, нужно вычесть из выборки среднее значение (и добавить 0.5 для удобства).
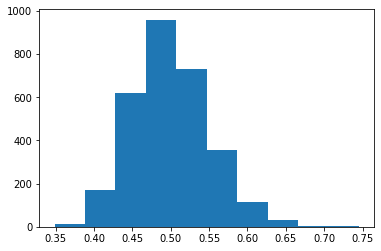
Та же выборка после выполнения описанной выше операции. Видно, что теперь среднее значение в районе 0.5
Также после каждого цикла обучения LDA менял какие-то параметры и удалял/добавлял колонки в таблице.
После нескольких циклов обучения некоторые топики уже получилось интерпретировать и распределение команд по кластерам тоже получило какую-то осмысленность. Хотя не стоит от этого многого ждать — как я писал ранее, команда не может целиком находиться в одном топике, поэтому строя такое распределение, мы теряем важную часть информации о контексте.

Для такого распределения усредняется статистика команды по всем матчам и подаётся в LDA. На выходе получается вектор с вероятностями попадания в топик. Для данного распределения выбирается топик с максимальной вероятностью.

Ключевые эвенты для топиков
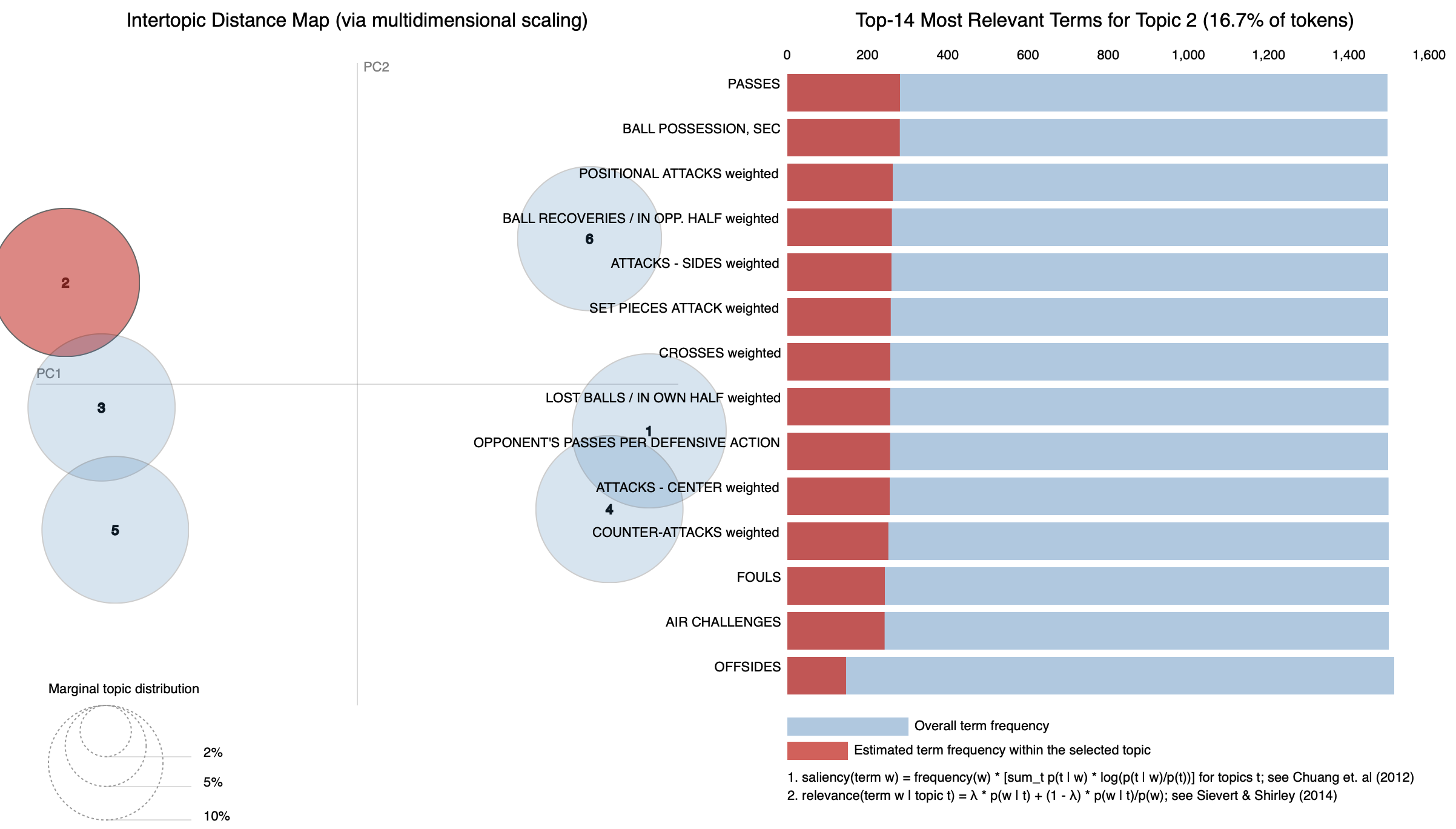
Визуализация, аналогичная той, которая использовалась для кластеризации текстовых документов в начале текста. На графике расположены все топики по их близости относительно друг друга и показаны все эвенты для этого топика
Каждый топик — набор наиболее показательных эвентов с их важностью. Например, топик 0 — классический стиль с позиционными атаками, большим количеством владения и передач, топик 3 — агрессивный вертикальный контратакующий стиль. К сожалению, по данным, которые я собрал, невозможно выделить много легко интерпретируемых топиков (на что также влияет большее количество чемпионатов, команд и матчей, чем в презентации, где речь шла о Чемпионшипе).
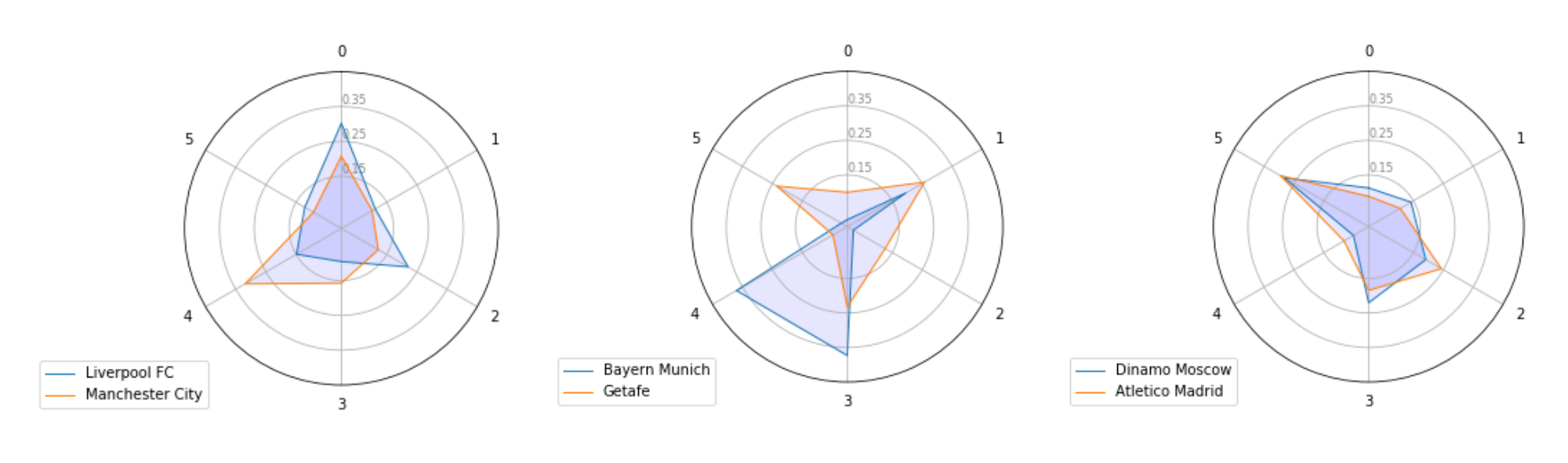
Сравнение радаров команд
В этой визуализации показано, с какой вероятностью команда в среднем подходит к каждому топику. Это можно назвать стилистическим профилем команды, сравнивая которые, можно сделать выводы о стиле и близости команд. Для построения такого графика на вход модели подаются все матчи команды и усредняются вероятности попадания в топики на выходе (разница от распределения по топикам в том, что там усреднялась вся статистика перед тем, как подавать не в модель).
В момент, когда у топиков появляется осмысленность, а по радару уже можно идентифицировать команду, стоит переходить к следующему этапу. Выше была дана формула для приближенного вычисления количества голов, забитых в матче одной командой. Эта формула, по сути, нужна для того, чтобы выразить и посчитать эффективность стиля, так как количество голов команды A, по предположению авторов, зависит от качества атаки команды A, качества обороны команды B и эффективности стиля команды A против стиля команды B. Конечно, это все очень условно, но достаточно для вычисления эффективности стиля в конкретных матчах.
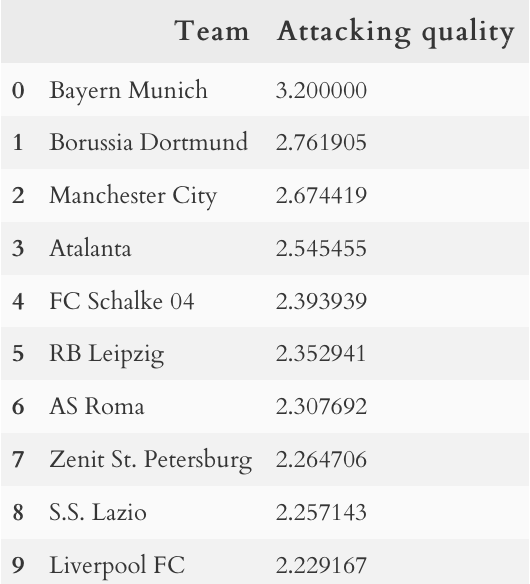
Топ-10 по качеству атаки. Результат «Баварии» может быть завышен из-за небольшой выборки в связи с недавней сменой тренера. «Зениту» тоже не стоит удивляться — естественно, в РПЛ они много в среднем забивают.
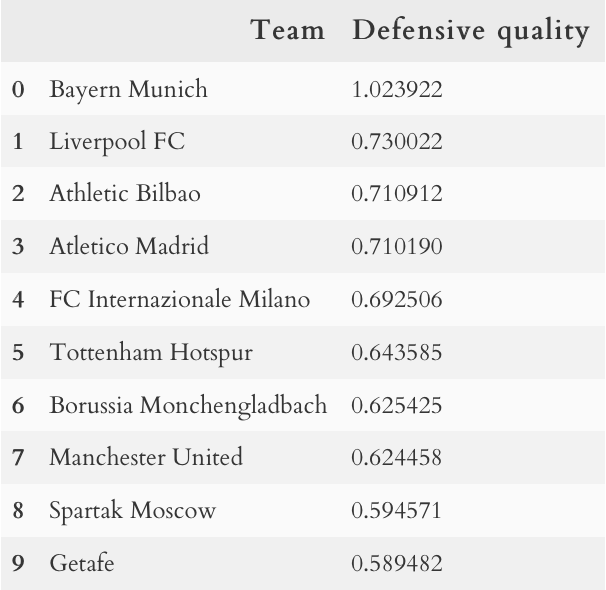
Та же ситуация с «Баварией» и «Спартаком»: у «Баварии» маленькая выборка, а «Спартаку» в РПЛ, похоже, действительно клубы забивают меньше, чем они забивают обычно. Также не стоит удивляться «Тоттенхэму» — у них также маленькая выборка из-за той же смены тренера, но они тут оказались благодаря своему везению, которое, вроде как, начало заканчиваться — слава дисперсии. Однако на остальные команды стоит обратить внимание. В «Ливерпуле» никто и не сомневался, но «Атлетико» явно показывает, что не смотря на проблемы в позиционных атаках, у них все еще одна из лучших оборон в Европе. Про прессинг и позиционную оборону «Хетафе» можно почитать на сайте, «Интер» и Менхенгладбах сделали огромный скачок в качестве игры в целом в этом сезоне и заслуженно идут на своих местах в чемпионатах, а вот насчет Бильбао я был очень удивлен: здесь нужно дополнительное изучение конте
Далее эффективность усредняется по каждой паре «стилей»:
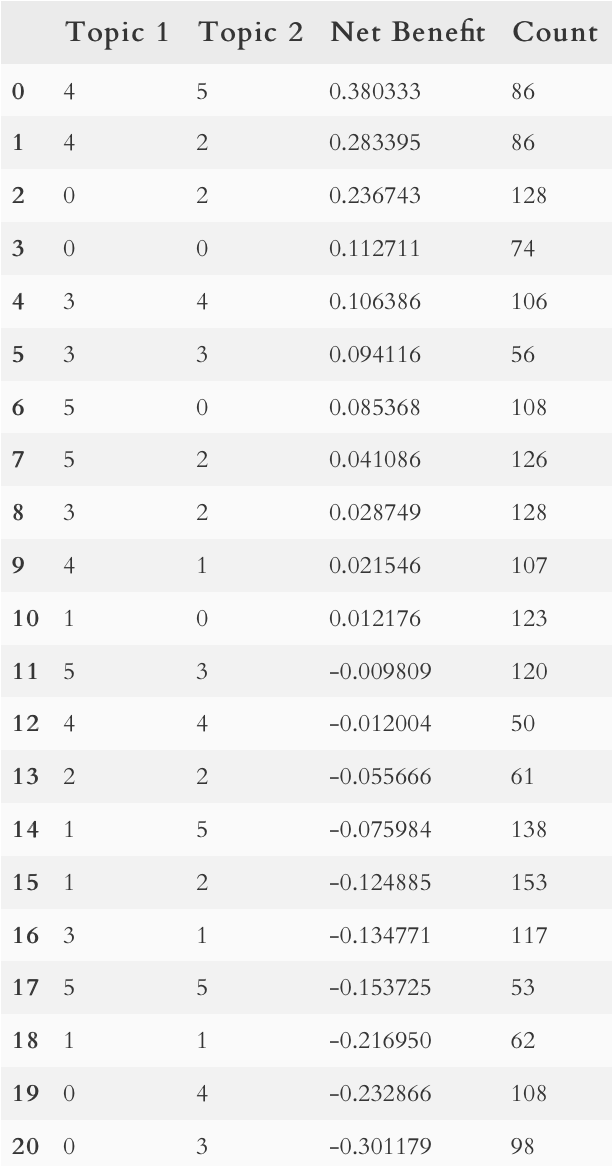
Таблица, аналогичная приведенной в презентации, за исключением того, что топики пронумерованы. Ключевые эвенты для каждого топика можно посмотреть выше
Посчитав эффективность, можно сравнить качество аппроксимации. Сделаем это очень прямолинейно — посчитаем разницу между реальными голами и разницей между качеством игры в атаке команды A и игры в обороне команды B. Затем учтем эффективность и сравним результаты.
Погрешность без учёта эффективности получилась равной 0.869, с учётом — 0.862. Погрешность понизилась, что говорит о правильной оценки стиля и работе модели.
Я уже говорил, что используя простой подсчет эффективности по формуле, мы теряем большую часть контекста, поэтому решил привнести в исследование кое-что своё — двуслойная линейная нейронная сеть, предсказывающая ту самую эффективность стиля. Преимущество в том, что вывод делается не только на основе двух доминирующих топиках в стиле команды, а на основе всех топиков с учётом их вероятности (по сути на основе стилистического профиля команд). После этого эксперимента погрешность упала до 0.852.
В завершение предлагаю посмотреть на предсказание модели относительно пары «Ливерпуль» — «Манчестер Сити»: для «Ливерпуля» модель выдает -0.11, для «Сити» -0.15 (эти коэффициенты, по сути, означают то, какая разница будет в матче между забитыми мячами и средним количеством забитых мячей в сезоне). Модель считает, что по «Сити» это противостояние ударит сильнее, с чем тяжело не согласиться.
Результат получился очень даже хороший, хоть и не идеальный, но для того, чтобы топики выглядели также красиво и легко интерпретировались, как в презентации, нужны данные соответствующего формата. В моем случае данные изначально давали понять, насколько качественно команда атакует (и как атакует) и как она прессингует. На такой основе достаточно тяжело сформировать много осмысленных кластеров, хоть и данные были более сложные и продвинутые, чем в оригинальном исследовании.
Для реального использования стоит взять даже более простые данные, но передающие более полную картину в целом. Вариантов использования много — можно искать похожих команд для анализа, подбирать тактику под соперника, оценивать, насколько догматична команда в своем стиле и тд. Также у исследования много перспектив: возможно объединить такое контекстное представление о команде с контекстным представлением игроков (player2vec) и предсказывать сочетаемость игрока с командой. Также распространение трекинговых данных должно улучшить результаты, так как с помощью них можно получать намного более полную картину о матчах.
Постараюсь позже добавить ссылку на код — сейчас он в недостаточно опрятном виде, чтобы им делиться.
